Authors: David Tsurel, Dan Pelleg, Ido Guy, Dafna Shahaf
Article can be found here
Trivia facts can drive users engagement, But what are trivia fact?
Is the fact “Barack Obama is part of the Obama family” a trivia fact?
Is the fact “Barack Obama is Grammy Award winner” a trivia fact?
This paper tackle the problem of automatically extracting trivia facts from Wikipedia.
In this paper Tsurel et al. focussed on exploiting Wikipedia categories structure (i.e. X is a Y). Categories represent set of articles with common theme such as “Epic films based on actual events”, “Capitals in Europe”, “Empirical laws”. An article can have several categories. The main motivation to use categories and not free text is that categories are cleaner than sentences and capture the essence of the sentence better.
According to Miriam-Webster dictionary a trivia is:
- unimportant facts or details
- facts about people, events, etc., that are not well-known
The first path Tsurel et al. tested was to look for a small categories a”presumably, a small category indicates a rare and unique property if an entity, and would be an interesting trivia fact”. This path proved to be too specific e.g “Muhammad Ali is an alumni of Central High School in Louisville, Kentucky”.
[TR] As commented in the paper this fact is is not a good trivia fact because the specific high school has no importance to the reader and or to Ali’s character. But, as stated later – when coming to personalizing trivia facts there maybe readers which find this fact interesting (e.g other alumni’s of this high school).
This led Tsurel et al. to the first required property of trivia fact – surprise.
Surprise
Surprise reflects how unusual the article with respect to the category. So they would like to define similarity matrix between article a and category C. A category is a set of articles therefore the similarity is defined as:

Surprise is defined as the inverse of the average similarity –
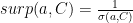
Example of results for this measure for Hedy Lamarr –

As you can see in the example above the surprise factor itself is not enough as it does not capture other aspects in Hedy Lamarr’s life (e.g. she invented radio encryption!).
Examining those categories and seeing that they are very spread led the team to the define the cohesiveness of category.
Cohesiveness
Cohesiveness of a category measures the similarity between items in the same category. Intuitively if an item is not similar to the other items in the category it might indicate that it is a trivia fact (or as mention later in the paper – detect anomalies).
Practically speaking the cohesiveness if category C is defined as the average similarity between each pair of articles in the category.
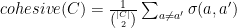
Hedy Lamarr’s results w.r.t to cohesiveness –

Tying it together
The trivia score of article a to category C is define as:

Interpret trivia score:
- Around one – this means that
. Meaning – the article is typical for the category, i.e. similar to other articles in the category.
- Much lower than one – “the article is more similar to other articles in the category than the average”. That means the article is a very good representative of the category.
- Higher than one – the article is not similar to the category, i.e is an “outsider” which make it a good trivia candidate.
Article similarity
Standard similarities methods don’t fit this case from 2 mains reasons –
- The authors look for broad similarity and not details similarities.
- Term frequency vector capture semantic similarity which sometimes get lost even after using normalization techniques.
Algorithm
- Describe each article by the top K TF-IDF in the text. The TF-IDF is trained on a sample of 10,000 wikipedia articles after stemming, stop-words removal and case folding. K=10 in their settings. The table below show the results for the articles “Sherlock Holmes”, “Dr. Watson” and “Hercule Poirot”. As one can see it captures the spirit of the things but there are not exact matches.

- To answer the exact match problem the authors used Word2Vec pre-trained model from Google News.
and
are the set of the top K TF-IDF term for articles
respectively.
- For each term in
![\sigma(a_1, a_2)=\frac{1}{Z}\sum_{i=1}^K w_{i}\cdot(max_{1 \leq j \leq K}\sigma(T_1[i], T_2[j]) +max_{1 \leq j \leq K}\sigma(T_2[i], T_1[j]))](https://s0.wp.com/latex.php?latex=%5Csigma%28a_1%2C+a_2%29%3D%5Cfrac%7B1%7D%7BZ%7D%5Csum_%7Bi%3D1%7D%5EK+w_%7Bi%7D%5Ccdot%28max_%7B1+%5Cleq+j+%5Cleq+K%7D%5Csigma%28T_1%5Bi%5D%2C+T_2%5Bj%5D%29+%2Bmax_%7B1+%5Cleq+j+%5Cleq+K%7D%5Csigma%28T_2%5Bi%5D%2C+T_1%5Bj%5D%29%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 

Further optimization on the computation such as caching, comparing only to subset of articles and parallel computation can be done when coming to implement this algorithm in production settings.
Evaluation
The authors evaluated their algorithm empirically against –
- Wikipedia Trivia Miner – “A ranking algorithm over wikipedia sentences which learns the notion of interstingness using domain-independent linguistic and entity based features.”
- Top Trivia – highest ranking category according to the paper algorithm.
- Middle-ranked Trivia – middle-of-the-pach ranked categories according to the paper algorithm.
- Bottom Trivia – lowest ranked categories according to the paper algorithm.
The authors crawled wikipedia and created a dataset of trivia facts for 109 articles. For each article they created a trivia fact for each algorithm. The textual format was “a is in the group C”.
Trivia Evaluation Study
Using the trivia facts above each fact was presented to 5 crown workers yielding 2180 evaluations.
The respondents were asked to agree \ disagree the facts according to the following statements or note that they don’t understand the fact:
- Trivia worthiness – “This is a good trivia fact”.
- Surprise – “This fact is surprising”
- Personal knowledge – “I knew this fact before reading it here”
The score of a fact was determined by the majority vote.
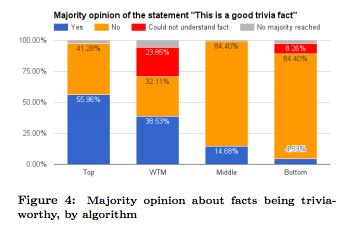
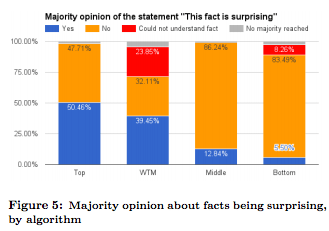
Result –
- The top trivia facts are significantly better than the WTM facts
- The consensus on the trivia worthiness of the top facts compared to the WTM facts is higher (32.8% vs 11.9%).

Engagement Study
In this part the team used google ad to tie trivia facts to searches and analyzed the bounce rate and time on page for the collected clicks (almost 500).
Results –
- CTR was not significantly different than reported results in the market (0.8) – i.e does not indicate willingness of users to explore trivia facts.
- Bounce rate (time of page < 5 seconds) for bottom trivia was 52%, for WTM facts 47% and for top trivia 37%.
- Average time on page was significantly better in top trivia comparing to bottom trivia (48.5 seconds vs 30.7) but was not significant comparing to WTM (43.1 seconds).
- One reason for people to spend time on WTM fact pages was because the presented sentences ware longer than the sentences presented for the top trivia and had a higher change of being confusing so people take time to understand them.
Discussion and Further work
Limitation – the algorithm works well for human entities but worse on other domain such as movies and cities.
Future work –
- Better phrasing of the trivia facts – instead of “X is a member of group Y” —> “Obama won Best Spoken word Album Grammy Awards for abridged audiobook versions of Dreams from My Father in February 2006 and for the Audacity of Hope in February 2008”.
- Turning trivia facts to trivia questions – for the example above generate a question of the form – “Which US presider is a Grammy award winner?” And not “Who won a Grammy award” or “What did Barack Obama win?”
[TR] – this would require additional notation of a good trivia question. The “good” question in this example is interesting since it involves a contrast between two categories.
Other applications –
- Anomaly detection – surprising facts are sometimes surprising because they are wrong. Using this algorithm we can clean those and improve Wikipedia reliability.
- Predict most surprising article in a given category
- Improve search experience by enriching result with trivia facts
[TR] – Improve learning experience on learning platforms by enriching the UI with trivia facts.
Extensions –
- Personalized trivia score – as commented above, different reader can find different facts more \ less interesting (see here) so the score should be personalized and take into account different properties of the reader such as demographic and even more temporal like mood.
- [TR] – Additional extensions involve trivia facts between entities such as “Michelle Obama and Melania Trump are in the same height”, “X and Y were born in the same date”.
