DALL·E 2 is a multimodal AI system that generates images from text. OpenAI announced the model in April 2022. OpenAI is known for GPT-3, an autoregressive language model with 175 billion parameters. DALL·E 2 uses a smaller version of GPT-3. Read more here, here, and here (the last one also slightly discusses Google’s image).
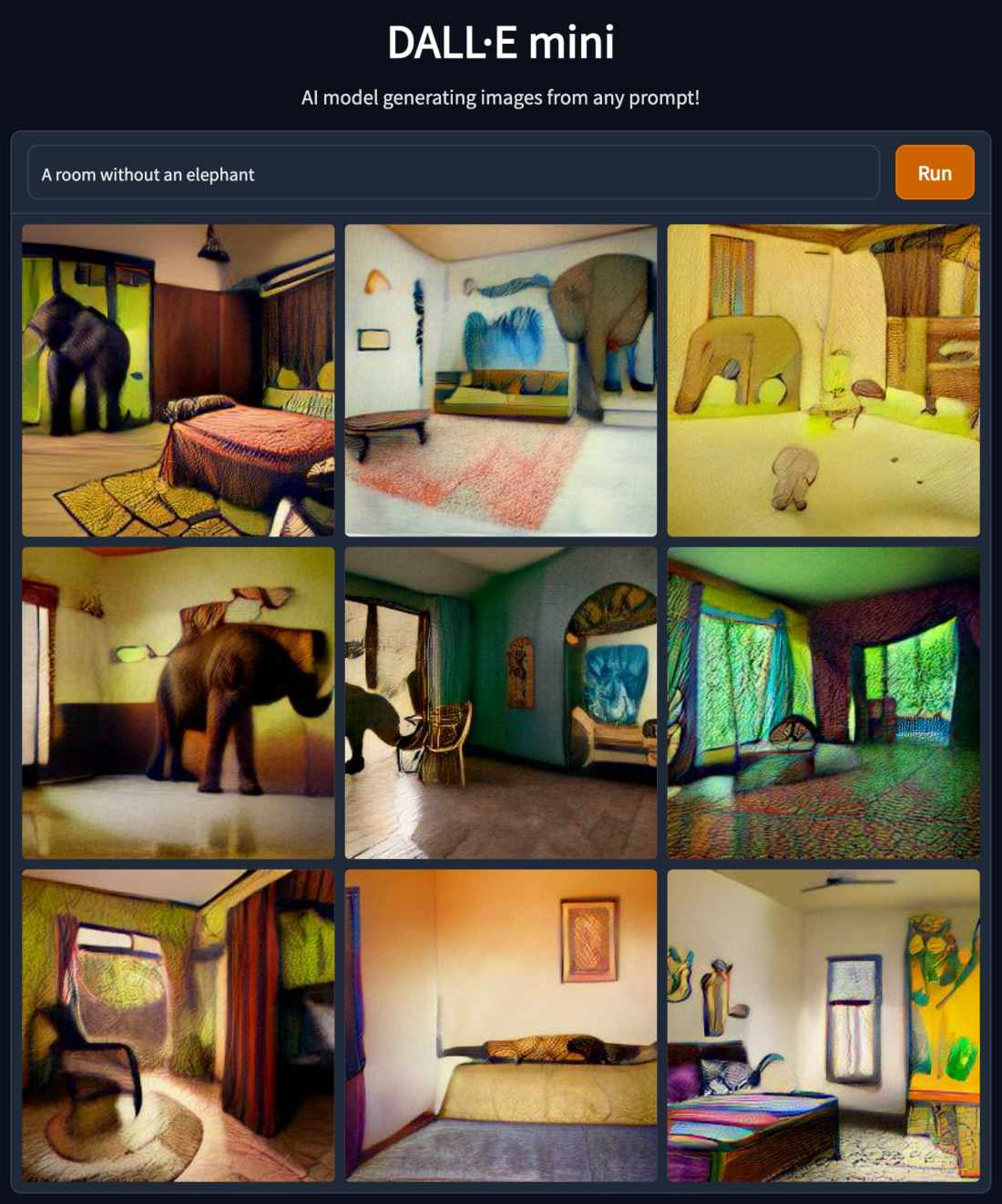
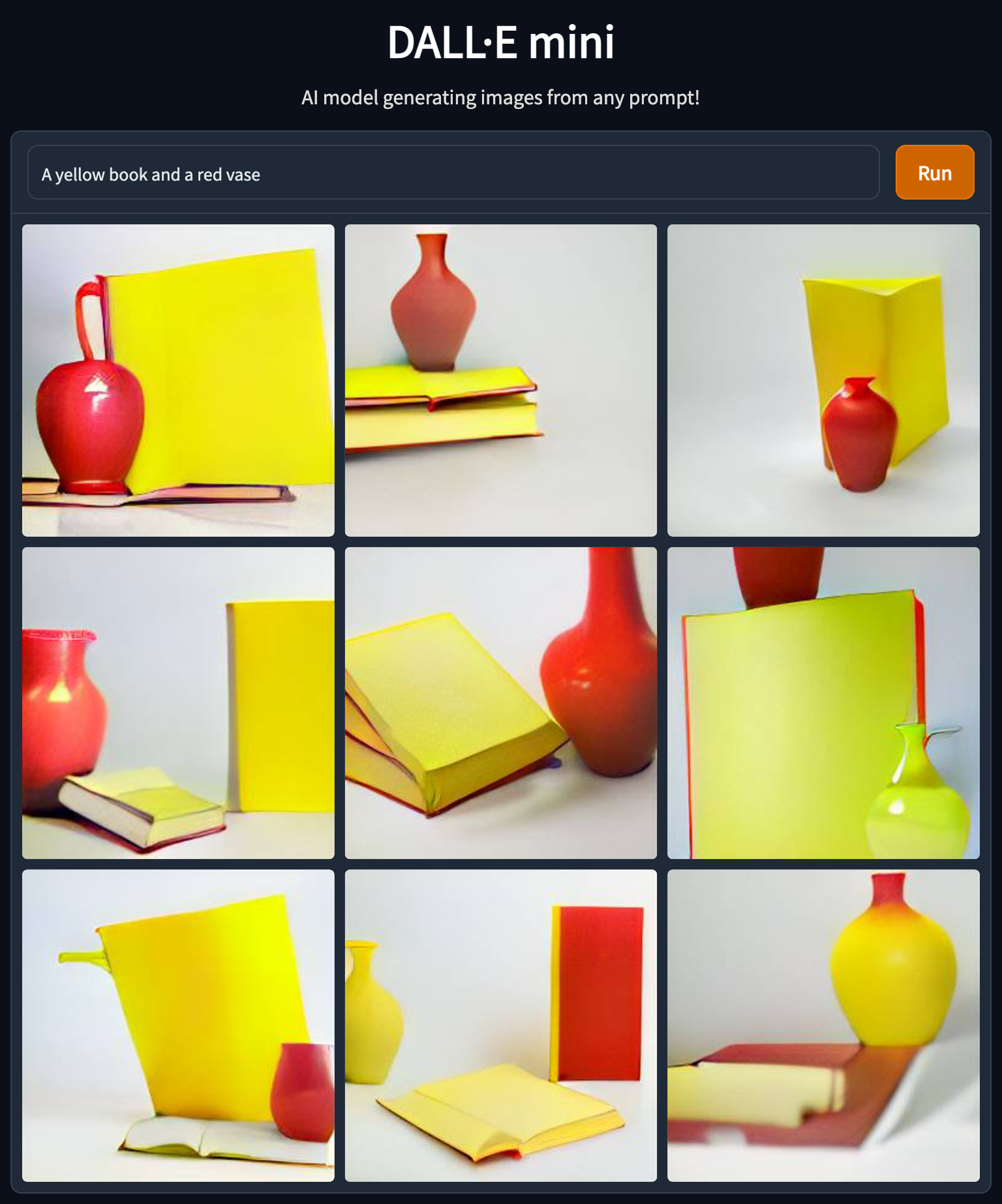
While the results look impressive at first sight, there are some caveats and limitations, including word order and compositionality issues, e.g., “A yellow book and a red vase” from “A red book and a yellow vase” are indistinguishable. Moreover, as one can see in the “A yellow book and a red vase” example below the images or more of the same, another drawback is that the system cannot handle negation, e.g., “A room without an elephant” will create, well, see below. Read more here.
Since I don’t have access to DALL·E 2, I used DALL·E mini via Hugging Face for all the examples in this post. However, the two models experience the same issues.

The model might have biases for example check all those software developers who write code, all men (also note that the face are very blurry in contrast to other surfaces in the images) –


I decided to troll that a bit to find more limitations or point-out blind spots. Check out the following examples –
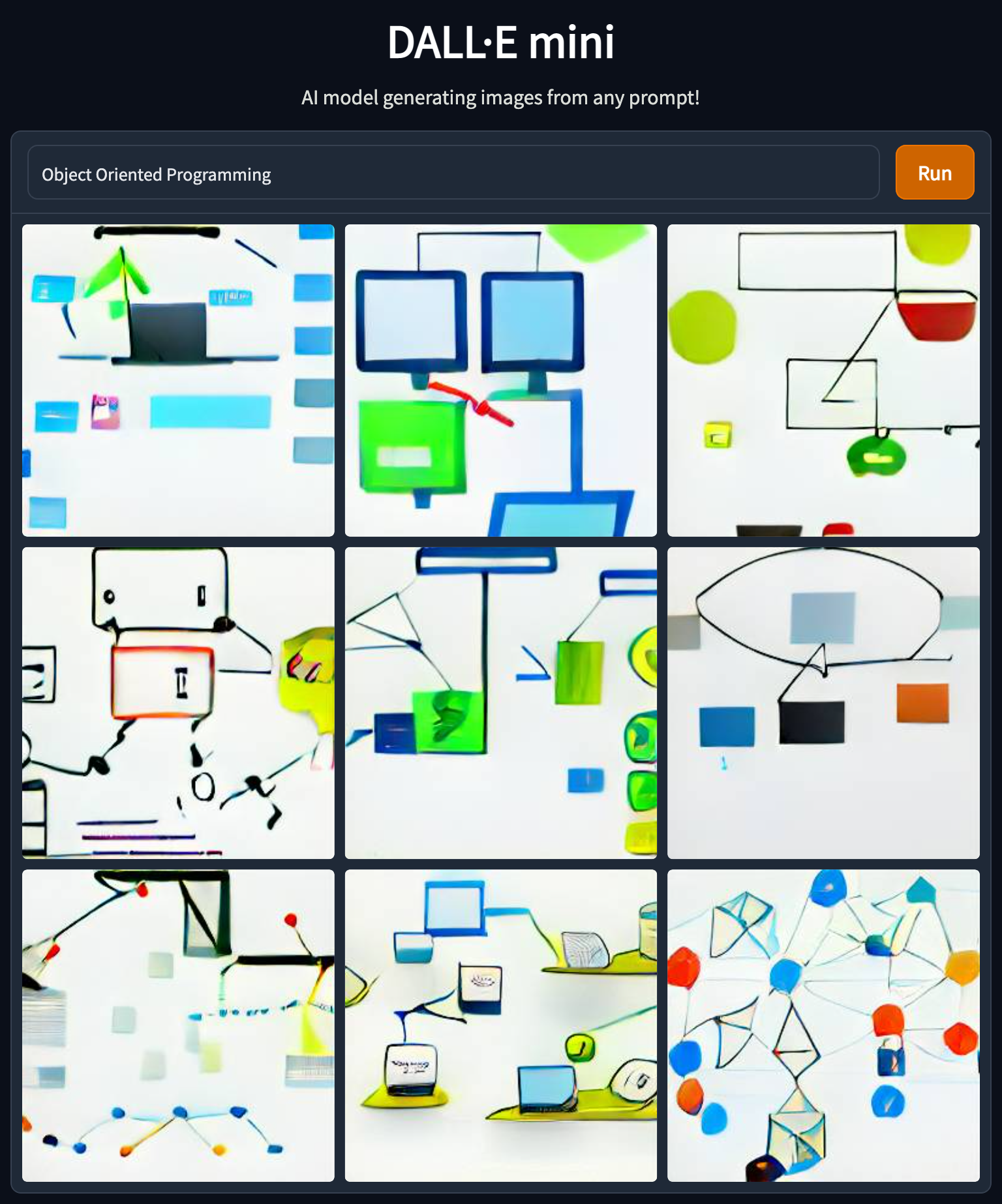
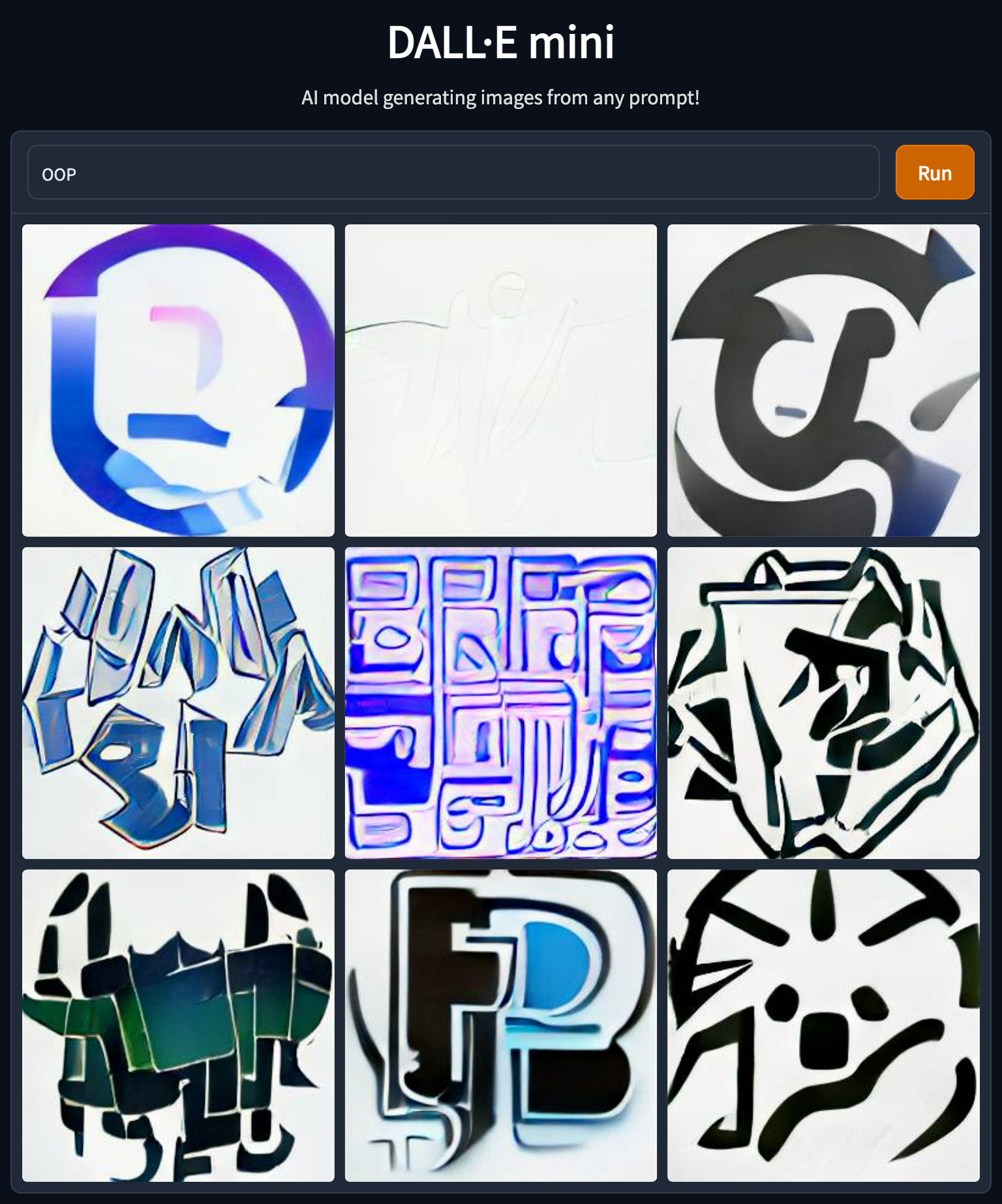

The examples above demonstrate that model does not handle abbreviations well. I can think of several reasons for that, but that emphasizes the need to use precise wording and might need to try several times to get the desired result.
Trying negation again (in this case, the abbreviation worked okish) –


Which of course reminds all of us of this one –

And a few more –


To conclude, I cannot see a straightforward production-grade usage of this model (and it is anyhow not publically available yet) but maybe one use it for brainstorming and ideation. For me it feels like NLP in the days of TF-IDF there is yet a lot to come. Going forward I would love to have some more tunning possibilities like a color scheme or control the similarity between different results (mainly allow more diversity rather than more of the same).
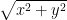
![\sqrt[\leftroot{-2}\uproot{2}3]{x_1^3+x_2^3+x_3^3}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B%5Cleftroot%7B-2%7D%5Cuproot%7B2%7D3%5D%7Bx_1%5E3%2Bx_2%5E3%2Bx_3%5E3%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\sqrt[\leftroot{-2}\uproot{2}3]{x_1^3+x_2^3+0.5 x_3^3}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B%5Cleftroot%7B-2%7D%5Cuproot%7B2%7D3%5D%7Bx_1%5E3%2Bx_2%5E3%2B0.5+x_3%5E3%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\sqrt[\leftroot{-2}\uproot{2}n]{\sum_{i=1}^n w_i x_i^n}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B%5Cleftroot%7B-2%7D%5Cuproot%7B2%7Dn%5D%7B%5Csum_%7Bi%3D1%7D%5En+w_i+x_i%5En%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.